This article was written by Dylan Thiam in May 2020. A special thanks to Francesco Quinzan
One example of where Open Data can be utilised is financing in the context of home energy-efficiency.
The benefits of Open Data are wide-ranging. From increased transparency to economic growth, Open Data will play an important role in the years to come.
There are currently several initiatives that aim to help the world transition to a low-carbon society. One of these is the Energy Efficient Mortgages Initiative (EEMI). The EEMI aims to create a standard green mortgage based on the hypothesis that energy efficiency can be used as a variable to predict the risk of residential mortgages and can, therefore, be a deciding factor when setting the loan terms.
An initial correlation analysis investigated the relationship between default risk and energy class. The results of the analysis proved that there is indeed a significant link between energy class and risk, as energy-efficient homes were twice as less risky than inefficient ones.
However, the sample size is not large enough to generate solid evidence. A part of the energy class data is available in a bank’s database but is not properly structured. It can be found externally, but cannot be retrieved due to personal data privacy issues specific to each country.
To overcome this issue, our hypothesis was that we could infer the energy class of a given house based on the existing, open data using a set of regression models.
This way, the regression models will generate a synthetic (or expected) energy class of all houses in a given portfolio. Such a portfolio would be then analysed using other machine learning-based credit risk models that take into account the energy efficiency class as a risk factor.
To do this, we decided to use the Open Data offered by the Lombardy region of Italy.
Dataset and Models
As we said, open data can strengthen credit risk modelling. By predicting the energy efficiency of the buildings posed as collateral, a financial institution can better determine the overall risk of a mortgage.
The dataset
The dataset, called CENED, consists of 47 features and 1.5 million observations, representing 60% of the entire residential real estate market in Lombardy.
At first impact, we noticed that the data quality starts improving from 1949 onwards. Before this date, the data were more chaotic due to the renovation of older homes and unorganised data collection.
It is also worth noting that most of the buildings in Italy were built after 1950. Thus, including the buildings built before 1949 would have only introduced excessive noise and would have given us little predictive capability due to an overly-complex model.
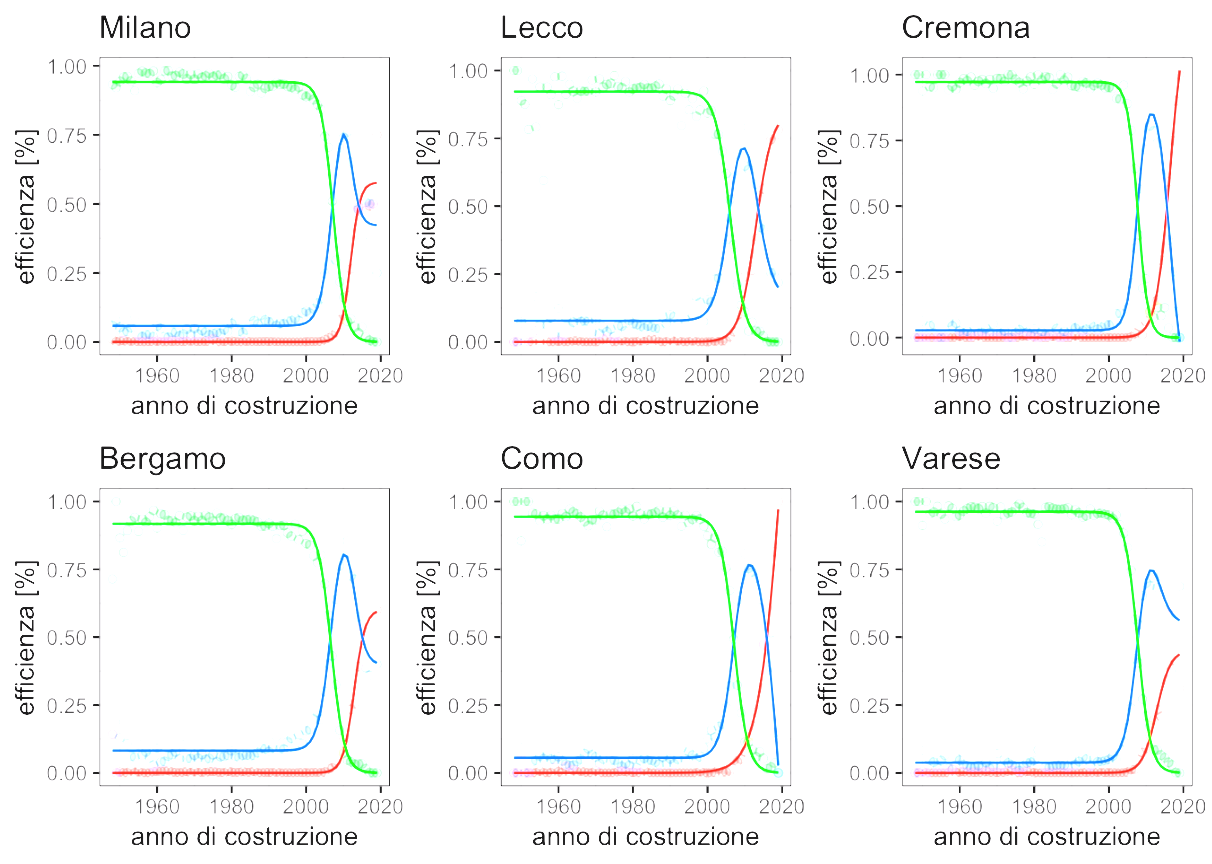
From the data, we can also see the effect that regulations had on the residential real estate market. In fact, from the 90’ onwards, more houses have a higher energy class. There are also some clear provincial patterns, which led us to believe that a province-specific model would better suit our needs.
The models
As a reminder, we aim at predicting the missing energy class of a residential building from the data of the same building the bank already has, such as postcode, property type, construction year, valuation amount etc.
Typically, banks store building data in the collateral section of a loan-level data type.
Benchmarking the ECB loan-level RMBS template, which is a good proxy for the loan-level data available in a bank’s database, the only variables that can be mapped against the CENED dataset are Postcode (field AR179) and Year of Construction (field AR60).
Thus, we built a set of models that take into consideration only two variables in the CENED dataset, respectively “PROVINCE” and “YEAR” as dependent variables; and Energy Efficiency Class as an independent variable.
For a more accurate prediction, we sorted the energy classes into three groups. Specifically, the buildings with an A/A+ rating are considered high efficiency; buildings with a B/C class are considered medium efficiency; buildings in the D/E/F/G class are low efficiency.
Following the grouping, we create the training and testing data. Put simply, for each energy group we choose 10% of the available data using a uniform probability. This makes it possible to have a randomised dataset which contains samples of each group.
Model Training
For each province in the dataset, we create an independent regression based on the sigmoid curve, parameterized by two variables. Afterwhich, we observe the regression for each province. The charts below shows the trends for the three groups of buildings:

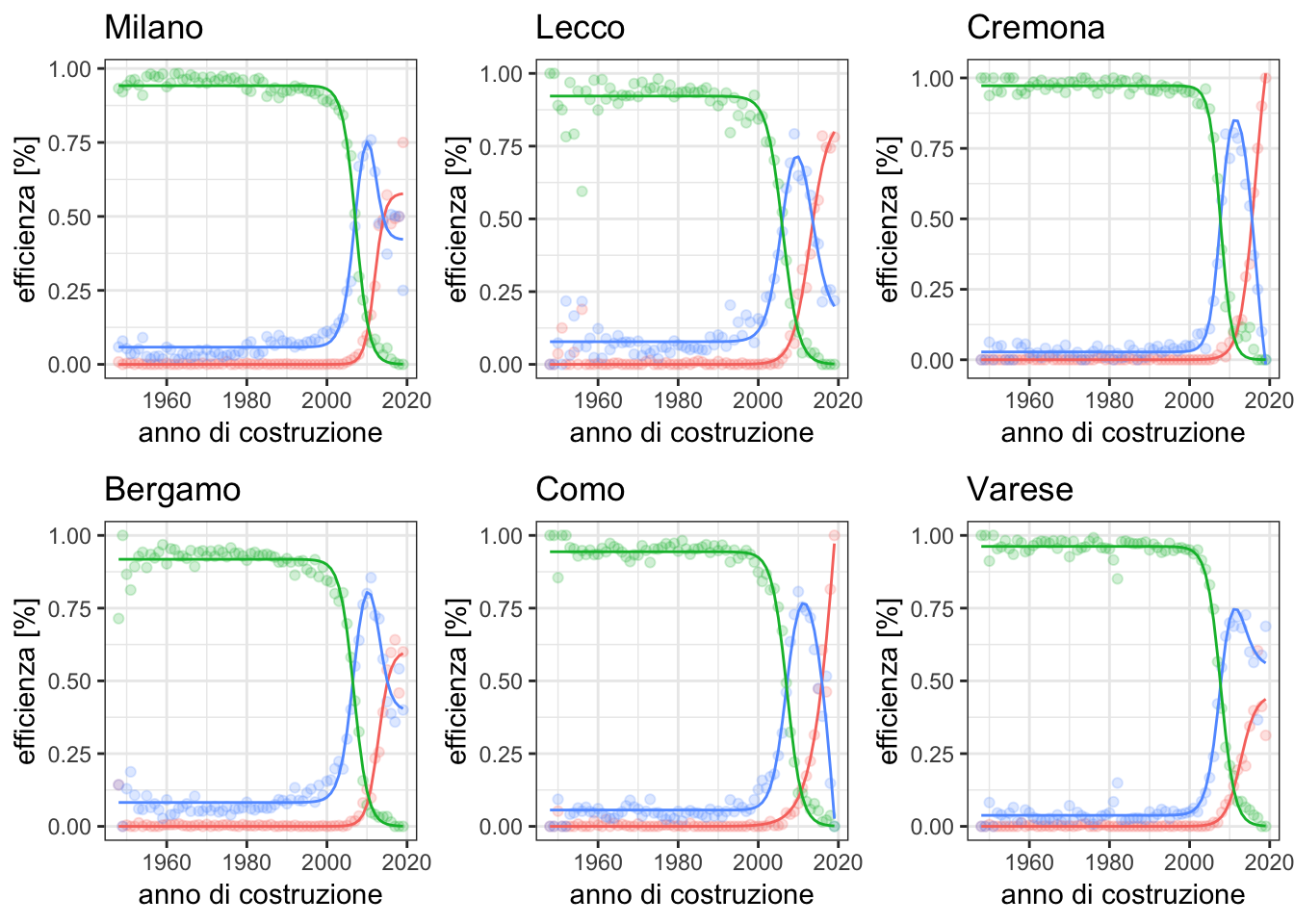
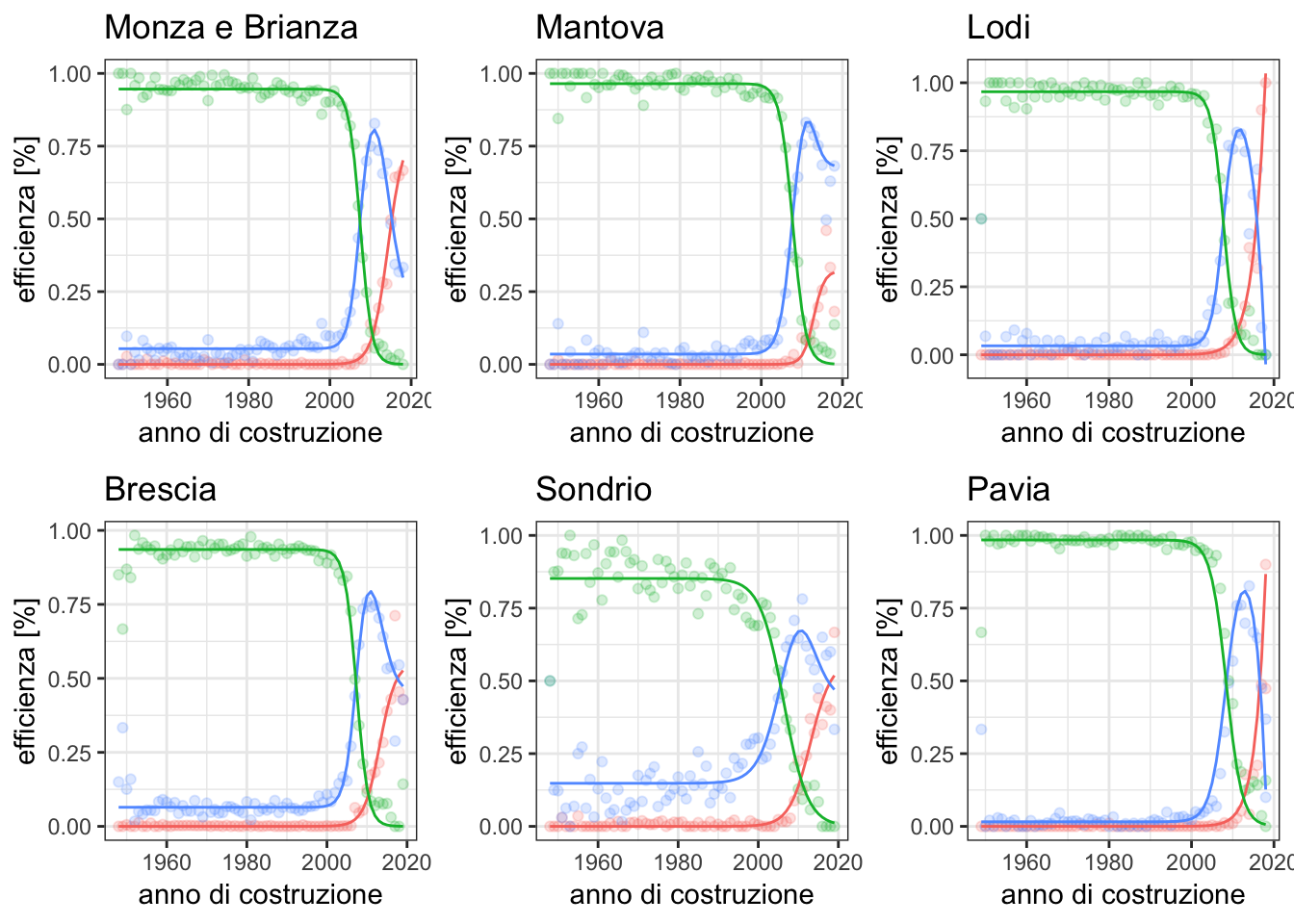
Model Testing
The model assigns an energy group to all of the buildings by municipality on a single sheet based on the regression. Observing the results of the first test, we can see that we have reached an accuracy of 0.7786, i.e. just under 80%.
Subsequently, if we scramble the features to create an error in the dataset, we can determine the accuracy of the results. In this second test, we found that the accuracy decreased substantially. Specifically, we reached an accuracy of 0.3317 (around 30%), which proves the prediction capabilities of our models.
More studies are needed in order to include other variables that for the time being we decided to exclude, such as FOGLIO and PARTICELLA. Including them would require more pre-processing to translate them into actual geographic coordinates.
Conclusion
It is clear how Open Data can bring value in a business context. Although we are at the very start of this “Open World”, we must start leveraging the relevant data that are open to us.
Of course, to even just handle the sheer volume of data at our disposal, the right tools are needed. But, before that, one must first be aware of the benefits and accept that this is where we are headed.
In fact, at this moment, experts claim that Open Data can be used in the fight against COVID-19. Others are contemplating the use of Open Data to move us towards Smart Cities for the benefit of citizens.
Businesses are using Open Data to enhance their existing services, optimise their processes and/or provide actionable insights derived from data analysis.
Financial institutions are in the position to leverage these same data to improve their risk assessment and monitoring activities. We are moving forward at an accelerated pace and being open is what it will be about in the near future.
Leave a Reply