Widespread adoption of deep learning models in highly regulated fields such as medicine and finance has been stalled by the lack of explainability. In fact, the high nonlinearity and complex mathematics of these “black box” models are an obstacle for financial institutions, who need to comply with rigorous regulatory standards. Algoritmica’s aim is to provide banks and other financial institutions with a viable explainability functionality within its core product – Deeploans – that does not compromise the usability and accuracy of the models.
The Basics: How Do Machines Learn?
Machine models learn by reducing the error over a specific objective function. It is thus important that the objective function accurately reflects the business problem. Then, by computing the loss function to measure the amount of error of the model, it will prove the model’s effectiveness.
Why explainability is crucial when it comes to credit decisions
Just as a doctor would not prescribe any personalised therapy based on a model’s unexplainable suggestions, a credit risk officer should not make repetitive decisions based on these same conclusions. As the whole point of these explainability techniques is to understand the reasons behind a machine’s decision, we must first and foremost understand the dynamics behind how the techniques work. Otherwise, we base our assumptions on falsehoods.
“Indirect” Explainability Techniques
The most commonly used explainability techniques to this date can be classified as “Indirect”: after training, models are opened up to observe the status of the internal parameters that were formed during training. A few examples: 1. Neural Activity Analysis – based on the visualisation of neuron activity that can give a general overview on how the information propagates inside the network. 2. Layer-wise Stratification Analysis – can be performed by using Principal Component Analysis (PCA) on the outputs of each layer of a model. In this way, one can reduce the multidimensional space of the output down to three main dimensions that can be visualised. Furthermore, one can also perform unsupervised clustering to observe the groups that the model has spotted in each internal layer. For instance, each group could represent a different country, which would mean that a particular layer is learning by geography. 3. Loss analysis over features elimination – can be performed by removing one feature of a group of features from the training procedure in order to see how much the model error increases, and in this way assess the importance of the missing variable or group of variables. Despite delivering relatively promising results, these techniques can be considered obsolete. The main problem with these techniques is that they can only provide a general overview of what was learned during training and highlight the most important variables that were used – and what was learned may not be fully applicable in prediction (i.e. unseen data).
“Direct” Explainability Techniques
Direct explainability techniques look at what the network does WHILE it predicts. In particular, we found the Temporal Fusion Transformer (TFT) model introduced by Bryan Lim (University of Oxford), Nicolas Loeff, Sercan Arik and Tomas Pfister (Google Cloud AI) quite enlightening. They presented TFT as a novel attention-based deep neural network model for interpretable high-performance multi-horizon time series forecasting.
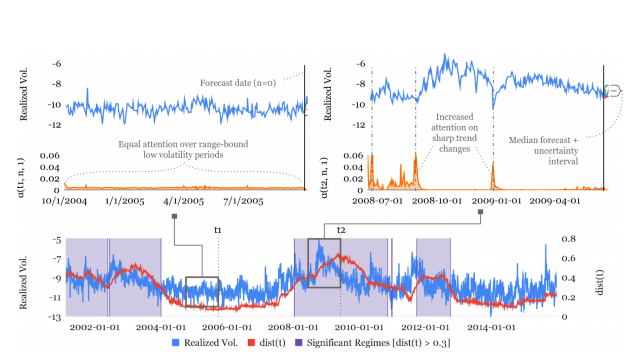
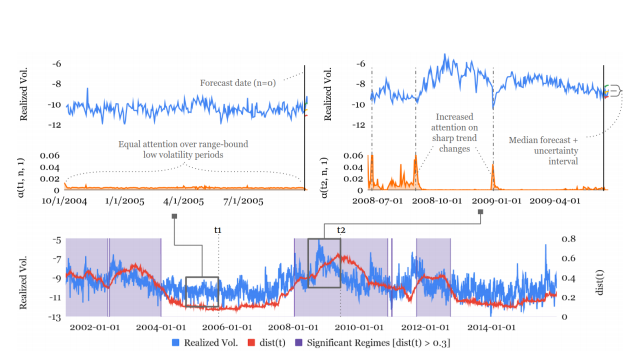
The concept of attention is central. It is the same as when someone watches a film. In a moment of nearly no action and absence of important information, not much attention is paid. However, at the introduction of details that are crucial to the understanding of the plot, one’s pupils enlarge. That enlarged pupil is the equivalent of the spike in the graph above. One can quite literally see what the machine is looking at. In fact, by analysing the components of the TFT attention layers, one can interpret the general relationships the TFT has learned and 1. Examine the importance of each input variable in prediction; 2. Visualise persistent temporal patterns; 3. Identify any regimes or events that lead to significant changes in temporal dynamics. In fact, attention-based models provide both perspectives: direct and indirect. And this is key because, as we said, indirect techniques can only provide a general overview of what was learned during training and which were the most important variables that were used. But these rules may not be fully applicable in prediction. Direct techniques, on the other hand, can directly highlight those variables in real-time using specific end-user data, which is typically different from training data.
A new attention mechanism for Deeploans?
The initial hypothesis was that this technique could fit well within our domain, i.e. SMEa, consumer lending and other granular asset classess. After a few tests, it became clear that TFT could help us achieve state-of-the-art forecasting performance. We are currently experimenting with multi-head attention architecture on a bigger portion of loan-level data and plan to make available a new set of pre-trained models for Deeploans users in the near future.
To summarise, using deep learning models without sufficient explainability is like running down a road with a blindfold on, with no sense of direction and having no idea if there is a cliff up ahead. Explainability helps financial institutions take the blindfold off.
Leave a Reply